test
Join multiple event streams within time window
· One min read
test

How to generate a flow of events having a timestamp, a random {key, value} pair and publish to Confluent Cloud?
With no line of code. For free.
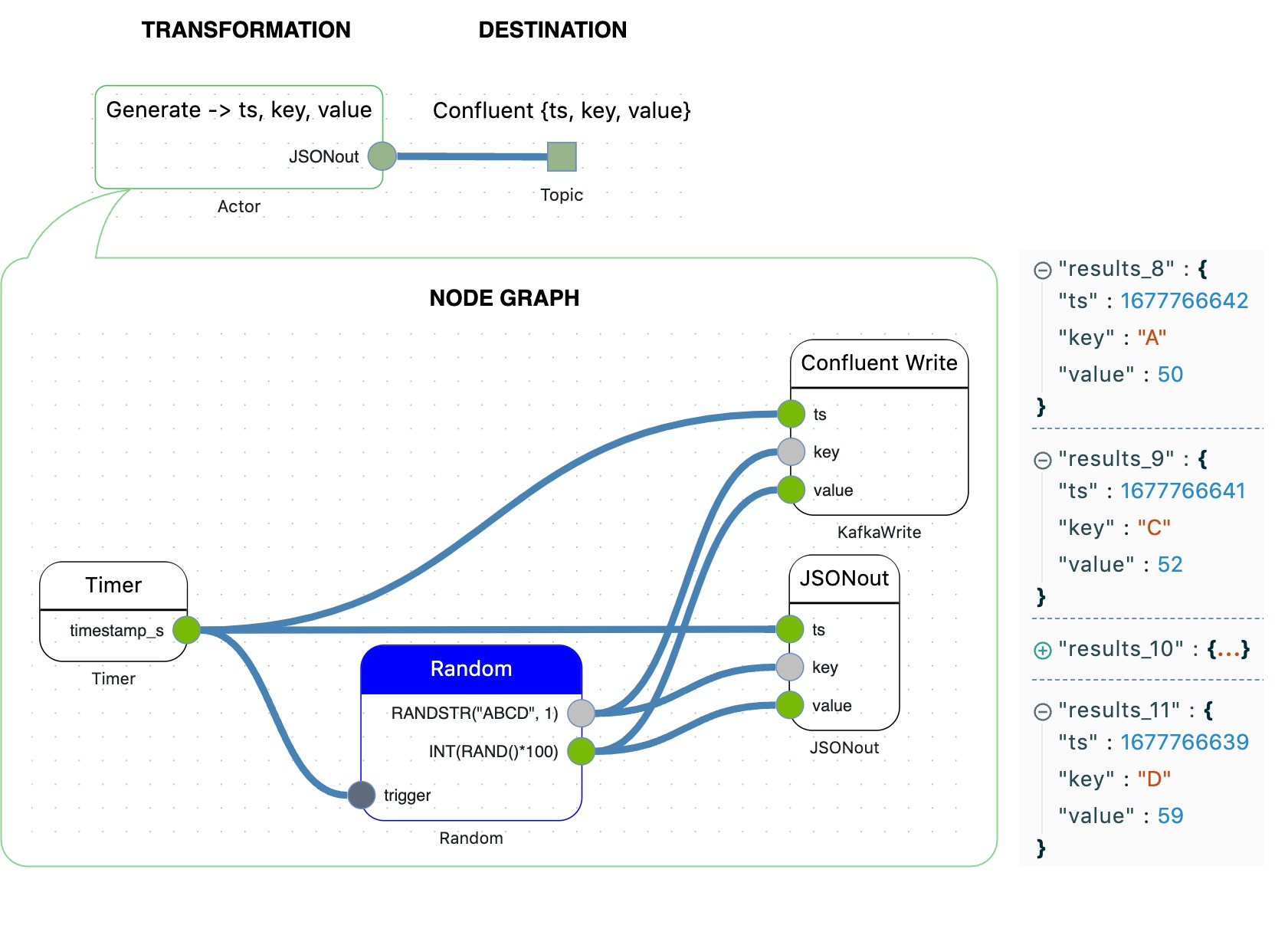
Let's repeat the excercise from the previous post.
We'll generate a flow of events having a timestamp, a random {key, value} pair and publish to Confluent Cloud.
The only difference is that we've to substitute the AWS SQS Write Node by the Confluent Write Node.
With no line of code.
How to generate a flow of events having a timestamp, a random {key, value} pair and publish to AWS SQS?
With no line of code. For free.
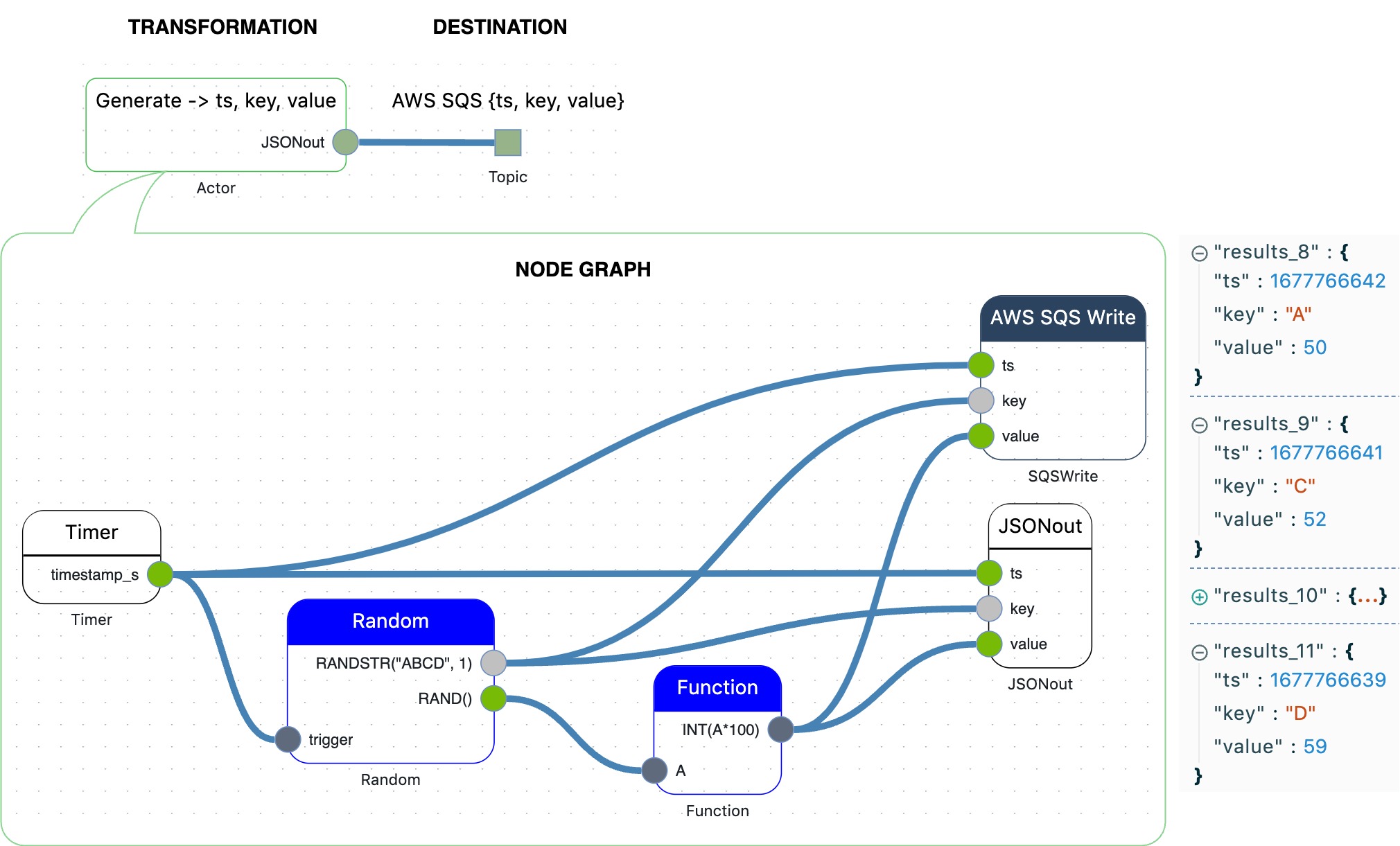
It is often hard to get access to real flows of events due to data sensitivity, security restrictions, approval issues, etc.
For prototyping purposes, real data may not be required. It is enough to generate data with the required characteristics.
In this Post we'll show how to generate a flow of events having a timestamp, a random {key, value} pair and publish to AWS SQS.
With no line of code.
Like every theater starts with a hanger, most of real-time event processing scenarios have the JSONin and JSONout Nodes.
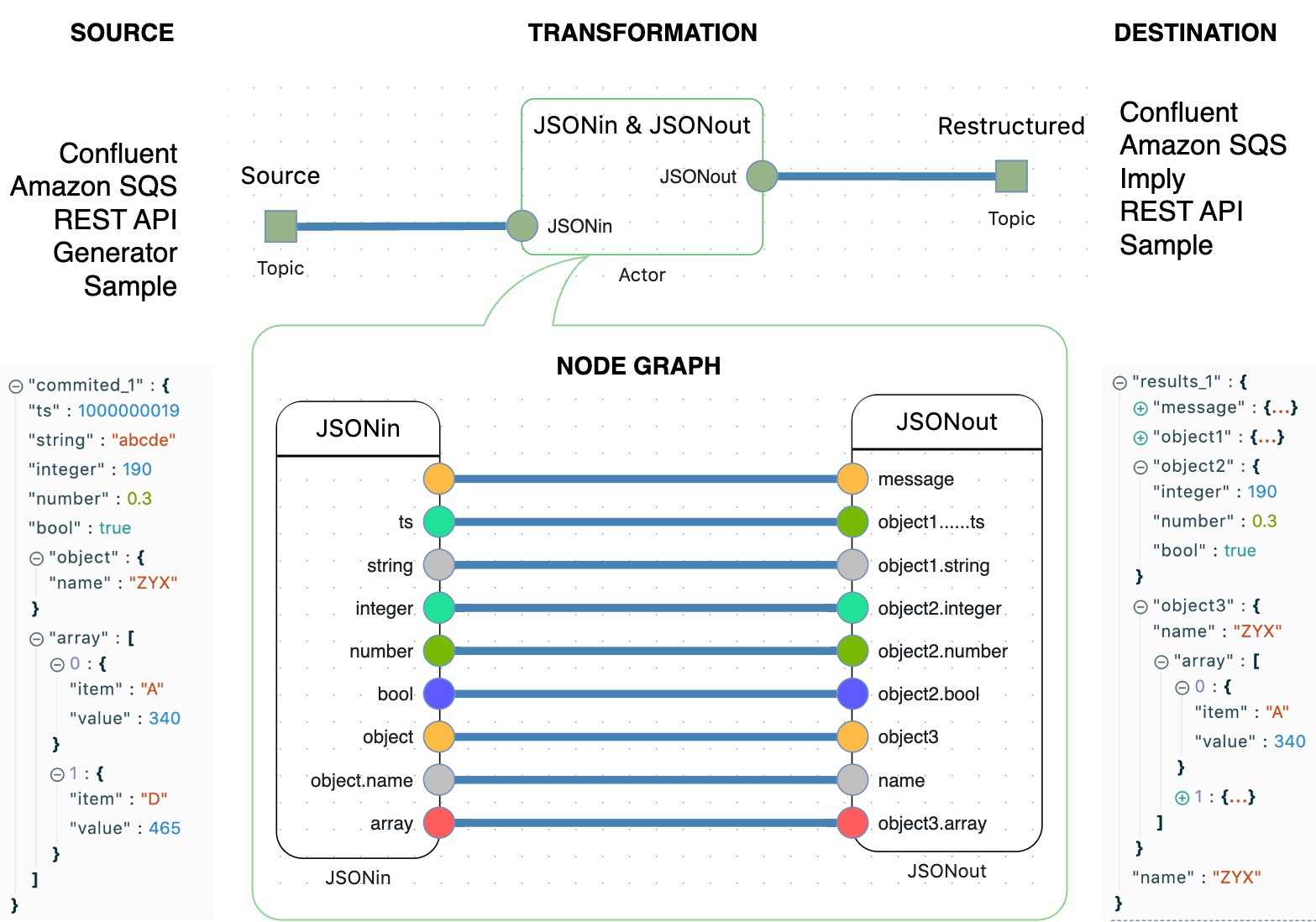
The JSONin and JSONout Nodes are used to create the processing logic on the level of elements of JSON messages.
The JSON messages are consumed from external services like #Confluent, #Amazon #SQS, #REST #API, sample files, or can be emulated by Nodes.
JSON is an extremely lightweight format and de-facto the standard for exchanging data. JSON messages transmit data objects of arbitrary nesting and complexity.

The flexibility of JSON is beneficial when it’s needed to get an order with an variable number of items, a complex application form, or a response from a REST API.
On the other hand, the versatility of JSON becomes problematic when one has to analyze a historical set of data or an online flow of messages.
If one needs the data in a tabular form to ingest into an analytical database or a spreadsheet, the nested JSON messages have to be denormalized.
Multidimensional complex JSON messages need to be flattened to become rectangular.
Imagine, you have an inbound flow of messages. It may be transactions, purchases, online activity, communications, device data, news, posts, whatever.
You need to consume this data and ingest into different tables.

There are lots of reasons to have different tables:
The messages may come from different sources like Message Brokers, Message Queues, Databases etc.
The destination tables may also be created in different Databases, or even Spreadsheets depending on the volume of the data and the usage patterns.
What you need is some tool to connect to inbound flow of messages, apply different conditions to the inbound messages to split the flow into multiple sub-flows, and ingest sub-flows into destination tables.
Every programming language starts by printing the “Hello, World!” phrase to some output.
But, actually, we live in the world of events and messages.
Messages are distributed via cloud queues, buses, brokers etc.
So, the more practical task is to print the “Hello, World!” message to a cloud message queue.
Imagine, that someone has an infinite flow of events and needs to split the flow into multiple sub-flows. It doesn't matter which events the flow consists of: transactions, clickstream, purchases, news, devices etc.
This problem is probably the most common.
There are dozens of reasons why it may be needed to split the flow:
And there are also hundreds of ways to split the flow:
The complexity of the problem is in high variability and volatility of splitting criteria.
Today someone needs to split the flow into 10 sub-flows, tomorrow into 100, and after tomorrow into 1000, quite different from the initial 10.
If any change takes 1 hour to apply, test, double check, move to production, handle errors, document, then 1000 hours are needed. If the process involves 2 or more teammates the hours must be multiplied. If any highly qualified technicians are involved, then not just hours, but also costs must be doubled.
But there are only 8 hours in a working day and the only budget.
“Flash, Flash, hundred-yard dash!” — do you remember this very funny and u-n-h-u-r-r-i-e-d sloth named Blitz from Zootopia? It pops up in the memory whenever we face someone’s slow performance or reaction. In fact, Blitz required only 10 seconds to reply. 10 seconds is not so much. In real life, we often have to wait much longer and waiting does not look so funny at all. Waiting is unpleasant and very expensive.
In this series of articles, I would like to talk about why we have to wait, how to stop waiting and what an interesting world opens up if we live at the same speed as reality. More precisely, let’s talk about the evolution of technological processes underlying the speed of data processing and decision making.
In 2015, Tyler Akidau, a senior software engineer at Google, published the manifesto “Streaming 101: The world beyond batch”. In 2018, this publication formed the fundamental pillar of a book on the evolution of data processing systems “Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing”.