
What’s the problem?
Imagine, you have an inbound flow of messages. It may be transactions, purchases, online activity, communications, device data, news, posts, whatever.
You need to consume this data and ingest into different tables.

There are lots of reasons to have different tables:
- Restrict access to tables for different users or applications.
- Provide different analysts with different data.
- Apply different processing logic.
- Decrease the volume and dimension of data.
- Filter, modify, enrich, map data before inserting into tables.
The messages may come from different sources like Message Brokers, Message Queues, Databases etc.
The destination tables may also be created in different Databases, or even Spreadsheets depending on the volume of the data and the usage patterns.
What you need is some tool to connect to inbound flow of messages, apply different conditions to the inbound messages to split the flow into multiple sub-flows, and ingest sub-flows into destination tables.
What’s the complexity?
The difficulty of the problem is in high variability and volatility of usage criteria.
Today you need to ingest data into 10 different tables, tomorrow into 100, after tomorrow into 1000, and conditions may permanently change.
You may need to duplicate data, filter out some attributes, select only required attributes, flatten nested objects, reject broken data, convert data type, enrich, or join data before ingesting into different tables.
If any change takes 1 day to apply, test, double check, move to production, handle errors, document, then 100 days are needed to support 100 tables.
If the process involves 2 or more teammates the hours must be multiplied.
If highly skilled technicians are involved, then not just hours, but also costs increase.
Why Nodes?
Fabrique Nodes offers a visual, intuitive, and lightweight approach to building message flow processing logic to overcome the complexity.

No DSL, no SQL, no Black box, no combinatorial explosion of complexity.
No code needed.

In the video we’ll show how to employ the Fabrique Nodes to connect to a cloud message queue, consume messages, apply some data processing logic, split the input flow of messages into 4 output sub-flows, and ingest the sub-flows into a destination cloud message queue without a line of code.
If you need to ingest data into another destination like Database, Message Bus, Spreadsheet, just choose an appropriate Node from the Collection.
If you need to consume a flow of messages from another source or change a processing logic, just choose an appropriate Node from the Collection.
Node Collection is extendable. If you can’t find a Node, just text us.
Try Nodes!
Fabrique Nodes provides Node Editor to build and test the message flow processing logic. Use Node Editor for free. Just authorisation needed.
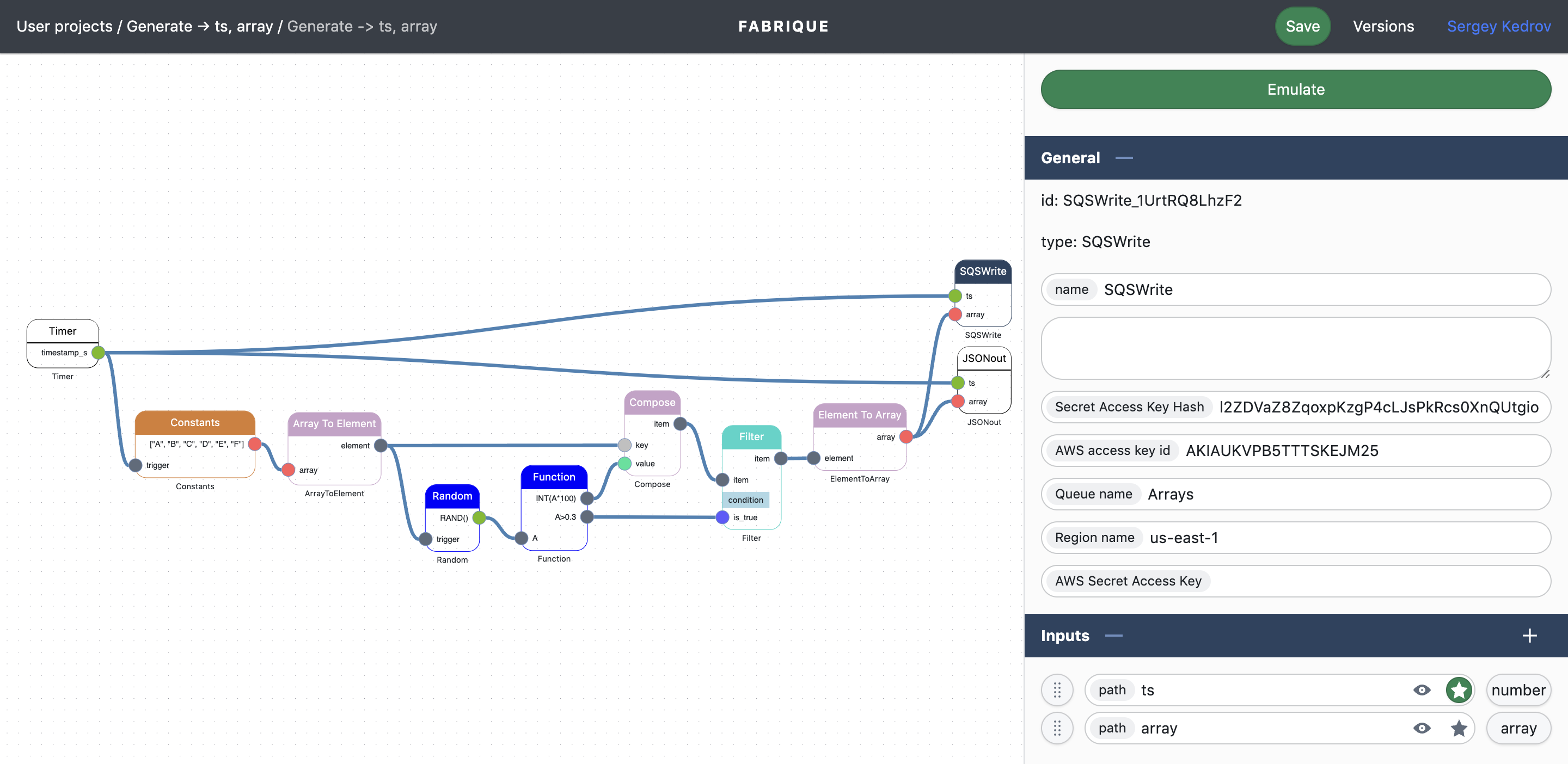
Fabrique Nodes grants the collection of Public Projects to clone and reuse some common scenarios. Watch the Public Projects to learn how to build your own logic.
Fabrique Nodes provides Runtime Environment to deploy and continuously execute the processing logic. Try it for free.
If you can’t find some Node in the Collection or have an idea of a Node, text us. The Node Collection is extendable.
If you want to build your own project and make it Public, text us. We’ll support you.
About
Fabrique Nodes is a cloud native scalable event flow processing service to solve problems such as data transformation, decision automation, real-time analytics, anomaly detection, data enrichment, AI integration without programming skills.
Event processing logic is built by the extendable collection of no-code Nodes. Fabrique Nodes allow to build direct asynchronous computational graphs of operations, and move the projects to production in 1 click. No code needed.
Welcome to Fabrique!