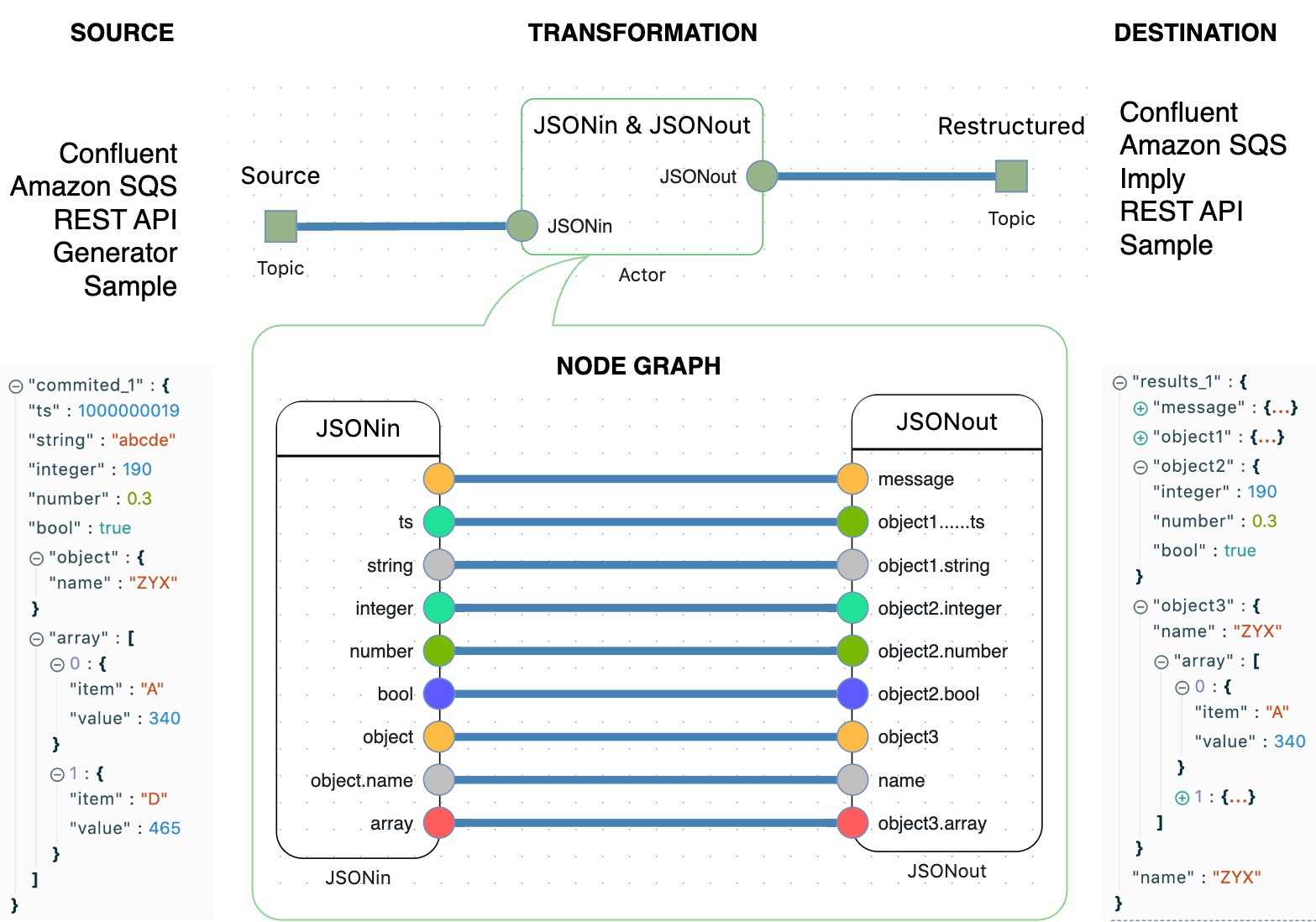
What’s the problem?
Imagine, that someone has an infinite flow of events and needs to split the flow into multiple sub-flows. It doesn't matter which events the flow consists of: transactions, clickstream, purchases, news, devices etc.
This problem is probably the most common.
There are dozens of reasons why it may be needed to split the flow:
- Restrict access to data for different users or applications.
- Provide multiple analysts with independent sources of events.
- Apply different processing logic to different sub-flows.
- Decrease volume and dimension of data.
- Filter, modify, enrich, map data in sub-flows independently.
- Prepare multiple tables to inject into an analytics database, etc.
And there are also hundreds of ways to split the flow:
- Duplicate or multiply the initial flow.
- Split the flow into non-overlapping sub-flows.
- Split the flow into overlapping sub-flows.
- Filter events from the initial flow by some rule.
- Apply conditions or transformations to sub-flows etc.
The complexity of the problem is in high variability and volatility of splitting criteria.
Today someone needs to split the flow into 10 sub-flows, tomorrow into 100, and after tomorrow into 1000, quite different from the initial 10.
If any change takes 1 hour to apply, test, double check, move to production, handle errors, document, then 1000 hours are needed. If the process involves 2 or more teammates the hours must be multiplied. If any highly qualified technicians are involved, then not just hours, but also costs must be doubled.
But there are only 8 hours in a working day and the only budget.