
What’s the problem?
Imagine, that someone has an infinite flow of events and needs to split the flow into multiple sub-flows. It doesn't matter which events the flow consists of: transactions, clickstream, purchases, news, devices etc.
This problem is probably the most common.
There are dozens of reasons why it may be needed to split the flow:
- Restrict access to data for different users or applications.
- Provide multiple analysts with independent sources of events.
- Apply different processing logic to different sub-flows.
- Decrease volume and dimension of data.
- Filter, modify, enrich, map data in sub-flows independently.
- Prepare multiple tables to inject into an analytics database, etc.
And there are also hundreds of ways to split the flow:
- Duplicate or multiply the initial flow.
- Split the flow into non-overlapping sub-flows.
- Split the flow into overlapping sub-flows.
- Filter events from the initial flow by some rule.
- Apply conditions or transformations to sub-flows etc.
The complexity of the problem is in high variability and volatility of splitting criteria.
Today someone needs to split the flow into 10 sub-flows, tomorrow into 100, and after tomorrow into 1000, quite different from the initial 10.
If any change takes 1 hour to apply, test, double check, move to production, handle errors, document, then 1000 hours are needed. If the process involves 2 or more teammates the hours must be multiplied. If any highly qualified technicians are involved, then not just hours, but also costs must be doubled.
But there are only 8 hours in a working day and the only budget.
Why Nodes?
If there are no constraints to solve the problem a developer could employ a lovely programming language, an analyst write a smart SQL query, an IT engineer deliver a reliable infrastructure, and a business person build a detailed process diagram. If!
In reality there are plenty of constraints: terms, staff, budget, skills, variability, maintainability, etc.
Reality pushes teams to look for alternatives in solving routine and repetitive tasks.
Splitting the flow of events into sub-flows is definitely a routine and repetitive task. No rocket science.
The alternative should not only fit the constraints, but also be intuitive for teammates with completely different backgrounds.
This is where visual no-code tools step in.
Fabrique Nodes bring a new approach to fit constraints and deliver an intuitive lightweight environment to build, test, execute, maintain, reuse, extend, and share the event flow processing logic.
No DSL, no SQL, no black box, no combinatorial explosion of Nodes.
Node Collection is limited for purpose by a dozen of typical operations to cover the most common scenarios and to shorten the learning curve. At the same time, the Node Collection is extendable and new functionality can be added without friction.
Try Nodes
To illustrate the approach, let’s take the inbound infinite flow of events represented by JSON messages having just 3 variables: a “timestamp”, a “key”, and a “value”. The “key” takes a random “string” value from the “A”, “B”, “C”, and “D” alphabet. The “value” takes a random number from 0 to 100.
Let’s split the input flow of events into 4 sub-flows in accordance with the letters of the alphabet.
JSONin Node

The JSONin Node reads the input JSON messages, transmits the entire JSON messages to the “empty” Output Port, decomposes the “key” element from the JSON messages, and transmits the value to the “key” Output Port.
The JSONin Node allows to decompose any nested element of a JSON structure except “array”. The “query” label in the “input” field shows the path to the element.
Function Node

The Function Node has Input and Output Ports. The Input Port gets a value for the “KEY” variable. The Output Port applies “formula” and sends “true” if “key”=”A”, or 'false” if “key” ≠ “A”.
Filter Node
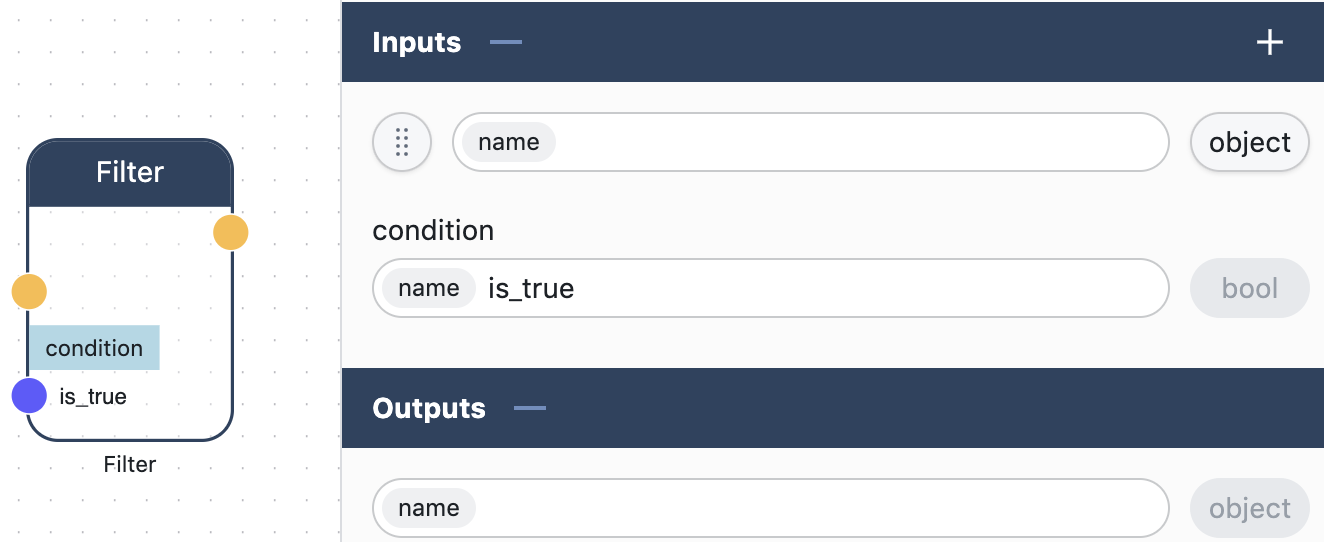
The Filter Node gets the entire JSON message to the “empty” Input Port, transmits the JSON message to the “empty” Output Port, if the input value in “condition” Input Port “is_true”.
JSONout Node

The JSONout Node has the only “empty” Input Port to get the entire JSON message and write it to the output.
The JSONout Node allows to add any number of Input Ports to get values, and compose nested JSON objects of arbitrary complexity to the output.
Link the Nodes
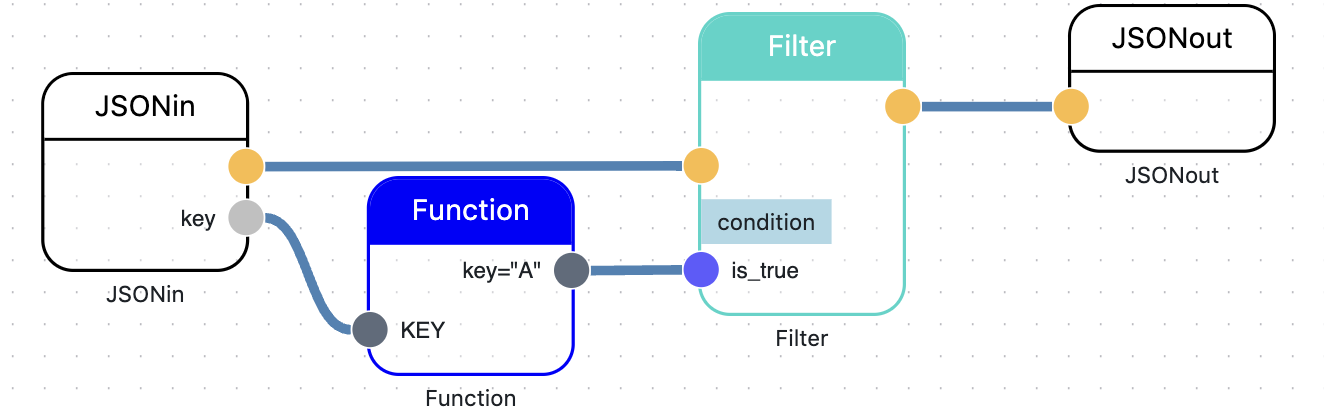
That’s it. The JSONin Node reads input messages, transmits the entire message and extracts the “key” element. The Function Node checks the condition. The Filter Node transmits the entire input messages to the output if the condition is true. The JSONout Node writes the filtered message to the Output.
Add conditions

The input flow of messages is split to 4 output sub-flows. No code is needed. The processing logic is represented by the Simple Node Graph which is intuitive for explanation.
No Monster Node Graph

Instead of building a Monster Node Graph it’s much more practical to decompose a complex processing logic into multiple stand-alone Simple Node Graphs.
The rule of thumb - make Node Graphs as simple as possible.
Simple Node Graphs allow to atomize and isolate the processing logic, computational resources, error handling, testing, collaborative work etc.
Simple Node Graphs are isolated from each other by Actors.
End to End Project

We started the demonstration with the statement that the inbound flow is taken from somewhere.
In real projects the flow of events is started from a message bus, queue, broker, and is finished by bus, queue, broker, REST Client.
The last image illustrates the Actors Graph. Each Actor executes a Simple Node Graph.
The ABCD Sub Actor connects to an external cloud queue, consumes JSON messages, and writes to the ABCD Topic. The Split ABCD Actor we have considered in our demonstration. The Actor splits the input flow of messages into 4 sub-flows. The A, B, C, and D Pub Actors publish the sub-flows to an external cloud queue. All the Actors work asynchronously.
Watch the video
You can watch this case step by step. The video takes 10 minutes.
The video covers the stages of the flow of events generation, subscription to the flow, creation of the actors, testing the project, deployment to production environment, and runtime execution.
What’s next?
- Sign in to Fabrique Nodes.
- Clone the project.
- Connect your own flow of events.
- Modify the processing logic.
- Connect the results to destinations.
- Share your project with your teammates.
- Make your project public.
About
Fabrique Nodes is a cloud native scalable event flow processing service to solve problems such as data transformation, decision automation, real-time analytics, anomaly detection, data enrichment, AI integration without programming skills.
Event processing logic is built by the extendable collection of no-code Nodes. Fabrique Nodes allow to build direct asynchronous computational graphs of operations, and move the projects to production in 1 click. No code is needed.